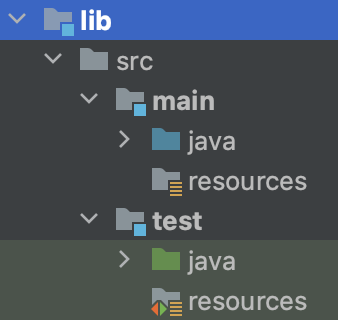
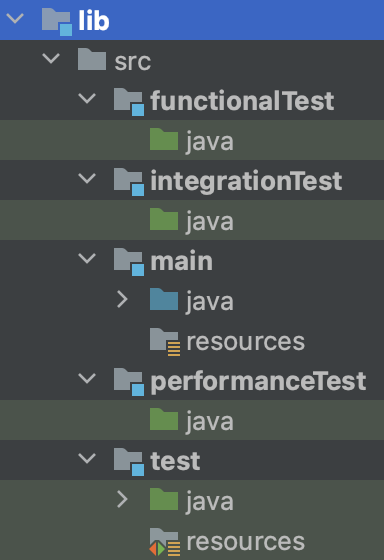
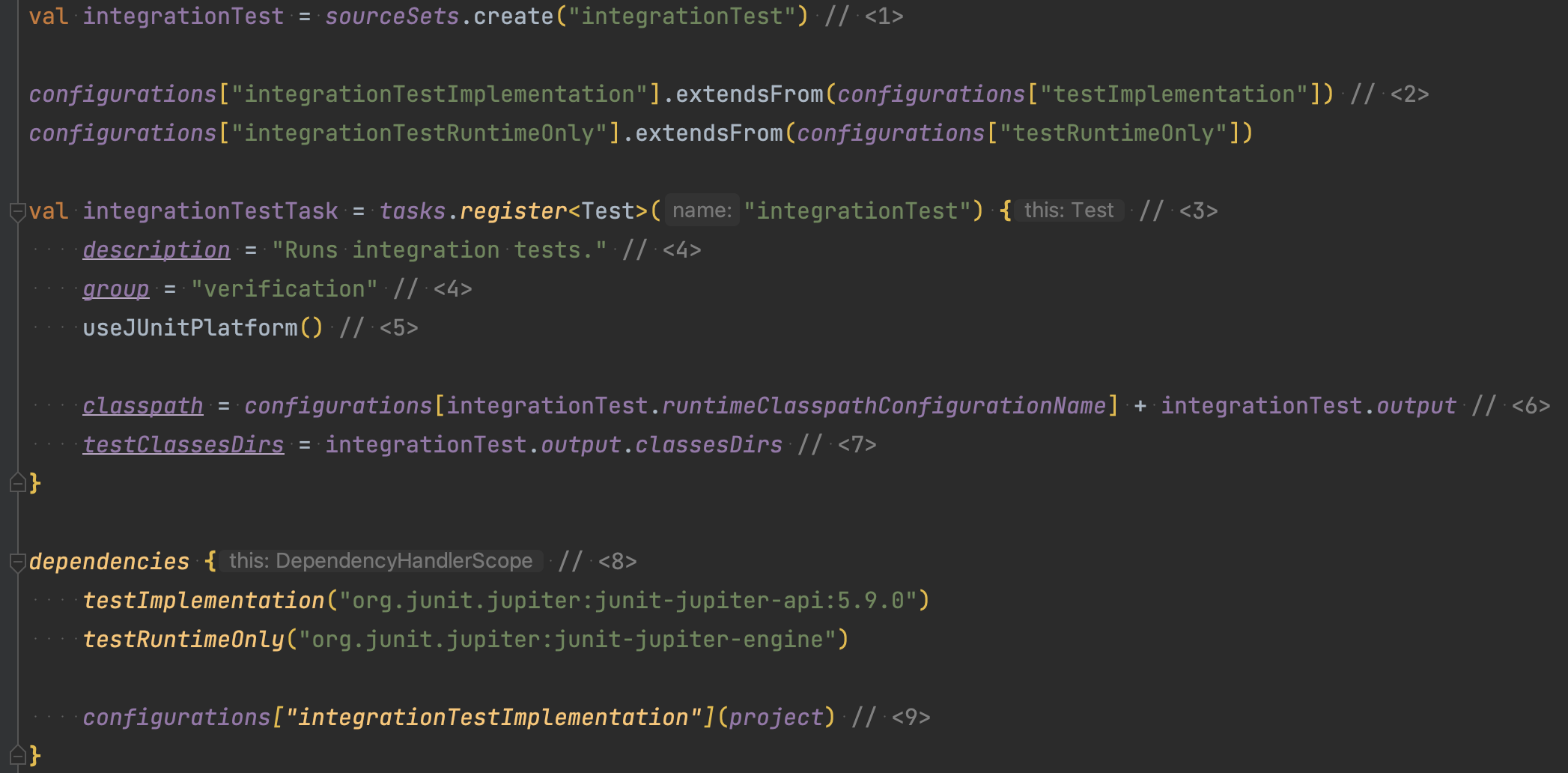
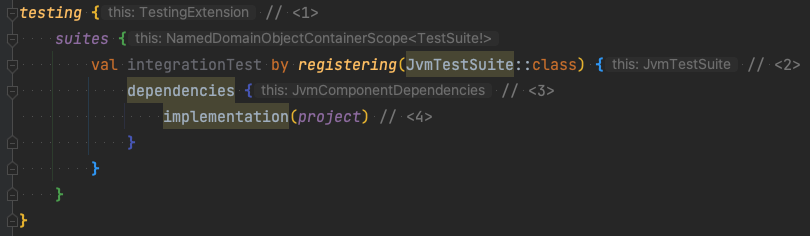
Introduction from Jon Haidt:
In my first book, The Happiness Hypothesis, I found that ancient wisdom about human relationships, consciousness, and flourishing holds up well in light of modern psychology. But as the digital age drowns us in exponentially increasing rates of new content—most of which is trivial and ephemeral—it is becoming clear that almost everything more than a few years old gets buried by incoming content. This is a serious problem for the continuity of any civilization if most writing and ideas propagate laterally (from peer-to-peer) and very little propagates longitudinally, from generation-to-generation. Our godlike technology may be cutting us off from the accumulated and hard-won wisdom of humanity.
But there are still communities that maintain ties to ancient wisdom, communities in which adults share the work of morally forming the next generation, not just their own children. The clearest examples are religious communities in which home, school, and house of worship are the three main institutions that, when well coordinated, will root children in moral traditions and protect them from anomie. We have already covered the ways that Jewish and Christian communities are doing this, beginning by making their schools, churches and synagogues phone-free zones.
Today we bring you one of the deepest thinkers about society, technology, and religion, Andy Crouch. Andy has been an editor at Christianity Today, and he is currently a partner at Praxis, an organization that fosters mission-driven Christian entrepreneurship. He is also the author of several books including The Tech-Wise Family and The Life We’re Looking For: Reclaiming Relationship in a Technological World. I first met Andy in 2022 when we were brought together via the Trinity Forum. We discussed the biblical story of the Tower of Babel, and the role of technology in bringing us into a second post-Babel era. We spoke together again in 2024 at a Veritas Forum event at NYU, titled Hey Siri, How Do I Find Myself? A Conversation on Spirituality & Technology.
In these talks and in his books, Andy has developed a way of speaking about technology as “magic” that exposes in an instant the damage done to the moral development (or “formation”) of children when homes, schools, and churches become saturated by smartphones and other technologies. I think his argument is so profound, and so urgent for everyone involved in raising or educating children, that I invited Andy to write up a version of it just for readers of After Babel.
– Jon
Where the Magic Doesn’t Happen

It’s amazing how often modern people talk about magic.
To be modern, almost by definition, is to live without putting much stock in a supernatural “beyond” to the world. And yet, nearly every time a new technology is introduced, its promoters reach back to the ancient idea of magic to capture its significance.
It was true of Steve Jobs at the dawn of the smartphone—Apple’s advertising for many years was saturated with promises of a “magical” experience. And now it is true of the next wave of tech. Sam Altmann of OpenAI opens a recent essay: “In the next couple of decades, we will be able to do things that would have seemed like magic to our grandparents.” Once you start looking for the technology-magic connection, you’ll find it nearly everywhere—especially in the promotion phase, before the technology actually arrives.
Even more surprising is how often we still talk about a specific magical tradition: the practice of alchemy. For centuries, alchemists sought to transmute all metals into gold, to escape the conditions of mortality, and perhaps even to create new forms of life that would answer to our command—all summed up in the quest for the substance known as “the Philosopher’s Stone.”
Now, if to be modern is to largely disbelieve in magic, surely to be modern is to know that the alchemists’ quest failed. If we think of alchemy at all, we think of it in contrast with a proper science like chemistry. The alchemists were wrong about the natural world—the chemists, after much trial and error, were right.1
So why is alchemy—a dead-end approach to the natural world—such a recurring theme in our own time? It is there, after all, in the best-selling novels in history, which had the Philosopher’s Stone right in the title of the first book—except in the US, where the publisher apparently judged that readers would miss the reference and changed the title to Harry Potter and the Sorcerer’s Stone. It’s there in Paolo Coelho’s mega-selling novel The Alchemist (it seems unlikely that a novel called The Chemist would have had the same success). It’s there, more subtly, in the title of Israeli historian Yuval Harari’s “brief history of tomorrow,” Homo Deus, which captures the deepest quest of the alchemists: to finally rise above our creaturely status and command the world like gods.
And then you read venture capitalist Marc Andreesen’s “Techno-Optimist Manifesto” from 2023 and find alchemy there not as metaphor, but as a straightforward statement of belief: “We believe Artificial Intelligence is our alchemy, our Philosopher’s Stone – we are literally making sand think.”
Here is what I think is going on. Alchemy failed as science, but it succeeded as a dream. Magic doesn’t “work,” in the sense that science works, but it does work as a dream. And technology is, after all, applied science. Applied to what? To a dream that was there long before science, the dream of magic.
Think of magic, for the moment, as the quest for instant, effortless power—the ability to get things done without taking time and without requiring labor or toil. In the absence of magic (or technology), getting anything done requires some amount of time, sometimes a great deal of time. But what if you could get results without waiting?
Likewise, in the absence of magic (or technology), getting anything done requires effort, sometimes substantial effort. But what if you could get results with just the wave of a wand, or swipe of a finger, essentially effort-free? (Actually, waving a wand might still be too much effort. Tesla’s release notes for their updated “summon” technology promise, “It’s like magic, but with more tech and less wand-waving.”)
Until the dawn of the technological age, when we invented reliable machines and the engines to power them, work was invariably constrained by both time and effort. All work, you might say, proceeded at the speed of digestion. Human beings and domesticated animals cooperated to turn organic processes into energy that powered nearly all our work in the world (though for a few purposes we learned to draw on wind or water power).
About a century ago, however, we turned a corner. For millennia humanity had pursued what the Greeks called techne—the art, skill, and craft of traditional tools. Once machines arrived, and once cybernetics and computation made them reliable, portable, and powerful in more and more domains, we crossed into a new story—the story of devices. It is no coincidence that at this point we adopted a new word for human ingenuity—no longer tools and the art of toolmaking, but technology, the art of device-making. Devices made possible for ordinary people what magicians had been seeking all along: to get results almost instantly, almost effortlessly, with almost no skill required from the user.2 In the technological era we no longer primarily acquire tools—we buy devices, and then upgrade them, in the quest to shrink that “almost” one step further.
The dream of magic, which eluded generations of alchemists to their great perplexity and frustration, has come true for us.
This sounds like it should be good news—and if your grandparents would be amazed, as Altman implies, to see what we will soon be able to do (the best magic, by the way, is always ahead in the future), there’s no doubt the alchemists would be thrilled. There is also no doubt that technology has relieved us of all kinds of tedium, which is why it seems so futile to imagine rolling back technology in most respects.
But there are some places, and some times, where we should absolutely resist the magic of technology, and where, if it has managed to insinuate itself, we should move as quickly as possible to limit it. Because there is one thing magic is absolutely terrible for, and that is the formation of healthy, thriving human beings—or to use a better and deeper word, the formation of persons at their best.
The reason magic is so bad at, and so bad for, the formation of persons is simple. Persons are not formed instantly, and persons are not formed effortlessly. And persons do have to be formed. We arrive in the world less prepared for survival than any other creature, far more in need of shaping and development. All the more so if we go beyond the mere requirements of survival and aim for something like flourishing. Flourishing, for human beings, absolutely requires formation.
What does it take to become a reasonably mature, reasonably wise, reasonably loving person? Inescapably, a great deal of time. Not just the years of cognitive and social development from infancy through adolescence into early adulthood—roughly 25 years from birth to the maturation of the prefrontal cortex. But also years of friendship, long hours of conversation, even the pause between hearing and speaking that marks the truly personal moment of really listening. In her 2011 book Alone Together, Sherry Turkle writes of the seven-minute mark at which conversations take a turn—the point when the usual opening gambits, pleasantries about weather or sports, have run out, there is a palpable pause, and someone has to take a risk. It takes seven minutes for a conversation, a real one, to even begin.
It is at the seven-minute pause, Turkle observed in her lab, that many people take out their phones, implicitly signaling to each other that the conversation need not go any further or deeper, an exit ramp before the unpredictable and vulnerable words beyond the silence. That, of course, was more than a decade ago. What are the chances that conversations last even that long these days? When you have magic in your pocket, why wait to see what will happen with a person?
If forming a person is inherently a time-bound process, it is also, obviously, anything but effortless. If you were to narrate the experiences that have most shaped you—especially you at your best—I am almost certain you would describe some combination of losses, accomplishments, joys, disappointments, and, perhaps, experiences of mercy or grace. What I am quite sure you would not include are times when everything was easy.
This means that we can extend our working definition of magic. Magic is (the quest for) instant, effortless, impersonal power. Because anything that is instant and effortless has little or nothing to do with persons. Magic has always been about circumventing the clumsy, awkward work of getting things done with persons. (Hence the elation behind the announcement, “We are making sand think.”)
In this, by the way, magic is almost the opposite of real science. All the “mad scientists” of lore—from Dr. Frankenstein to “Doc” Brown in Back to the Future—are actually alchemists in all but name, crazed figures on the margins of society chasing a new kind of power. Real scientists (I happen to be married to one, an experimental physicist) are not mad—they are generally quite sane, and do their work collaboratively and relationally, as well as painstakingly and often slowly. Science, far more than we generally see in popular representations of it, is a profoundly personal endeavor.
It is fascinating that when we actually began to make real progress in understanding the world, the dream to which we chose to apply the findings of science was not primarily making this careful, slow, fruitful process more and more a part of human experience, but to give ourselves something like the very opposite.
Instant, effortless, impersonal power is now all around us, and it is not going away. But we have let it colonize places where not only is it of no use—there is no magical way to raise a child—but where it actively displaces and undermines the essential process of personal formation. We have let the magic of technology into the formative stages of life—infancy, childhood, adolescence—so that from very early on, many if not most children experience the seductive power of instant, effortless results delivered through screens and digital devices (and many battery-powered toys as well).
And while these stages of life are singular and essential, magic is equally disastrous at other formative moments. A friend of mine found himself seated on an airplane departing Los Angeles next to a couple en route to their honeymoon in Hawaii. He observed with growing horror as the newly-married young woman opened up TikTok on her phone, began scrolling and swiping through videos, and did not stop, even for a bathroom break let alone a word to her husband, until the plane landed five hours later. One can only wonder how the rest of the honeymoon unfolded. Even and especially when we face the defining seasons of our lives, the temptation to use magic to evade their demands as well as their gifts can be—as every one of us knows one way or another—overwhelming.
If magic has colonized the formative stages, short-cutting and indeed short-circuiting the slow and patient process of becoming who we at our best want to be, it also has threatened the formative contexts where the great majority of persons are shaped, not just in the tender years of life but to some extent throughout the lifespan: home, school, and (for many though not all persons) religious communities.
Each of these is, and ought to be, a supremely formative environment. At home we are welcomed into the world and oriented to our fundamental identity and responsibility, and not just during childhood, since being a parent is every bit as formative in its way as being a child. At school we are inducted into a cultural tradition and given the rudiments of creative participation in that culture. And most human beings find themselves claimed by a religious or spiritual tradition that orients us to something (or Someone) beyond ourselves, holding out a demanding and ennobling vision of who we are meant to be, as well as a path toward that destination.
To put it plainly: for each of these formative contexts, there is absolutely nothing more corrosive and undermining of their very purpose than to introduce instant, effortless, impersonal power.
Take school as an example. As teachers and administrators scramble to address the “homework apocalypse” brought on by fluent Large Language Models, they suddenly find themselves trying to explain to students (and many parents) that the very point of education is that it takes us through the time-bound, difficult, but also relationally rich experience of gradually scaffolding the skills and knowledge that are necessary to become persons of genuine creative capacity. A student who uses an LLM to answer every question will certainly have a kind of power (the kind many students are most interested in—the power to pass the test), but what they will be entirely missing is personal formation, along with the personal relationships that actually make the difficult work of learning possible.
This is why we have to draw a bright line between the many contexts where magical tech is truly useful, and the contexts where it is actively harmful. Indeed, while I have lots of questions about how beneficial various technologies actually are in the workplace, say, I’d gladly make a deal where the inventors and promoters of technology could colonize every sphere of life—but in return would completely, totally, withdraw from home, school, and church. These should be places where the magic doesn’t happen.
And likewise, this is why we have to treat technology differently in the formative stages of life—why kids on screens are so much worse off than adults on screens, even if they seem to be having the magical time of their lives. As the Covid pandemic began, I happened to be reading Maryanne Wolf’s Reader Come Home: The Reading Brain in the Digital World, where she summarizes the evidence that there is a brief window for acquiring reading fluency in the late single-digit years—so that children who do not learn reading in those years may become ”functional“ readers but never “fluent” ones. It dawned on me that we might be about to deprive the pandemic-era cohort of 8- and 9-year-olds of instruction that could never have the same effect again. But I have come to wonder if the same basic pattern applies to the processes of becoming socially fluent that seem to happen in early adolescence (middle school in the United States)—and if our provision of the option of magic (through the magical and unreal parasocial worlds conjured up by “social” media) is causing a whole generation to miss out on experiences and learning they will simply never be able to repeat.
The more I have pondered these matters, the more convinced I am that our own family’s decision to have no screens of any kind available to our children before double digits robbed them of absolutely nothing they needed and protected them from much that would have actively harmed their growth as persons.3 Of course, the reason small children are given screens is rarely because they ask for them—what small children ask for, to an overwhelming and exhausting extent, is our personal attention. We give children screens—at home and school, and maybe at church as well—mostly not to solve their problem, but to solve adults’ problems.
I am not saying there is no role at all for technology at home, school, and church or other religious communities. There are some things for which there is no non-technological substitute. Effective vaccines, for example, are practically instant, effortless, impersonal solutions to diseases that ravaged previous generations. Safety, in general, can be greatly increased through technological means: should you be in a serious car accident, an airbag may well instantly, effortlessly, and impersonally save your life. Where safety is the goal, bring on the tech—though in formative contexts, safety should not always be the goal.
And there are also in every setting—including home, school, and faith community—certain tasks that are best described as drudgery: tasks that do not require or develop skill, are not really valuable occasions of relational formation, and cannot be done with any particular creativity. At home, laundry comes to mind. I see no great downside in outsourcing some of these tasks to quasi-magical devices—though the tale of the sorcerer’s apprentice should caution us that even commissioning a broom to carry water can go astray.
But far more of what we do at home is only drudgery if, deluded by dreams of magic, we let it become so. The preparation of food, which can be outsourced to a chain of magic from supermarket to freezer to microwave, is far better seen as an opportunity to participate in a meaningful, creative, bonding endeavor. And at formative stages, even low-skill tasks teach important personal qualities: patience, endurance, and learning to whistle while you work. So wise parents, teachers, and religious leaders will in fact sustain contexts where we build character through otherwise tedious tasks (never forgetting that finding the fun in a job, as Mary Poppins knew, comes far more naturally to children than to adults). This will be far easier when what children observe adults doing is not pressing one magical button after another, but modeling and creating deeply involved, demanding and rewarding non-magical experiences in which both children and adults take responsibility for timeful, effortful, relational work.
All this will require, if we take it really seriously, rethinking the purpose of home, school, and church, each of which has been to an extraordinary degree colonized by consumer culture’s expectations of magic—what I call in my book The Tech-Wise Family “easy everywhere.” The home, in particular, now seems to many of us like the place where life is meant to be easy—where we put our feet up and are entertained by magical screens in every room. We have almost entirely lost the pre-modern reality of a home that, rather than being one end of the binary pair of toil and leisure, was the unified context for work and rest. In that kind of home children saw adults exercising meaningful skill and apprenticed alongside them in becoming masterful with the materials of the world, but also saw and joined them in laying down their tools and taking up their instruments when the day or the week came to an end. To take magic out of the home would mean that we remove or radically marginalize the quintessential leisure experience of the modern home, watching television, and replace it with what all pre-technological people did at home once the work was done: tell their own stories and make their own music, acquiring skill and creating extraordinary inheritances of folk and high culture along the way.
Going down this path sounds truly fantastical to most people, and while there are many reasons people will give you that it could never work, when you really get down to the heart of the matter you realize that the core objection to making our homes, schools, and faith communities less magical is not even, “That is too hard,” but “I am too exhausted even to try.” If we give children screens to solve adults’ problems, the core problem adults—and increasingly children—have is that we are simply drained by the escalating demands of life in a world we were told was going to get easier. But we are not just exhausted because life and work have gotten busier and more complex—we are also exhausted because we ourselves have dwindled in our resourcefulness, our resilience, and our restedness. And we have dwindled because, in the end, we are unformed.
The less formed we are, the more dependent on magic we become. And the costs of this dependence are becoming clear—as documented so thoroughly on this Substack—not just to childhood but to the prospects of a flourishing society.
Yet here I want to inject a note of real hope. There are two kinds of tales about magicians that get told in Western literature. On the one hand, there is Faust, his soul so consumed by magic that it is ultimately carried off to hell—the magician who holds out to the bitter end, remorse and regret coming too late. But on the other hand, there is Prospero—the magician who breaks his own staff. When he does so, suddenly the whole cast awakens, set free from the spell, returned to life and reality.
What I have observed over and over since I started writing about these matters is that life and reality are still, astonishingly, close at hand. When a family, or a school, or a church takes a radical step to break the spell of digital devices, there is indeed a brief period of disorientation and dysregulation. And it is followed by a kind of emptiness, the kind that happens at Sherry Turkle’s seven-minute mark, the uncertainty of how we should actually proceed together now that the devices are gone. But amazingly quickly—in a matter of days for a family on a phone-free vacation, in a matter of weeks for a school that removes the screens, over the course of even just a one-month church-wide digital fast—we rediscover each other and rediscover the world.
Friends of ours send their children to a two-week camp every summer with three rules: no phones, no watches, and no mirrors. They told me recently, “The day our children come back from camp is the healthiest we ever see them.” Just two weeks is enough to be restored to health, especially in formative stages. All we have to do is renounce the magic.
And there is one last benefit of giving it up, at least in our formative stages and places. If there are two kinds of magicians in the Western imagination, Faust who clings to magic and Prospero who renounces it, there are also two kinds of magic. One, the magic of the alchemists, is the quest for domination and control of nature and whatever powers may lie beyond nature. But there is another magic, best captured by the idea of the enchanting—the sense, often unbidden and seen only out of the corner of our eye, that something wonderful, awesome, majestic, and mysterious is afoot in this world, something for which control is simply not the right word, indeed something which we would not want to control for fear of diminishing its beauty and its goodness. If the quest for the first kind of magic drives a prideful quest for power, the second kind of magic produces in us something much closer to humility.
For almost ten years now, I have started my day by going outside, well before I look at any screen. In the morning quiet, and this time of year the morning dark as well, the stars may be bright, or the sky may be the darkest of grays, with clouds low overhead. Some mornings it is raining, on a few mornings snow is falling. Whatever the weather, I stand out there, usually longer than I planned, feeling . . . small. I am just a creature, I think, as I take a few slow breaths. I am part of something so much larger than myself. And most mornings, I find gratitude and prayer rising up almost involuntarily.
Out here, I am no magician, but I am in the presence of a deeper and truer magic than the alchemists dreamed of. Back inside the house, the screens await me, and when they start glowing they will tempt me to enlarge myself and shrink my world to that very small part which I can control and master. But for a few crucial moments, real life seems worth the wait, worth the effort. It is worth it to not settle for anything less than the personal.
I want this for my children and my grandchildren. I want it for our frenetic and anxious society, so much in need of formation and so poorly served by our addiction to magic. And as 2025 begins, I am strangely hopeful that we are actually going to change course and break our wands. The year 2024 will probably be remembered for many things, but thanks in no small part to this Substack and its readers who are beginning to pursue collective action, I believe it actually may be remembered most of all as the year when the tide turned, when the quest for magic started to lose its luster, and where, in the times and places that matter most, we decided to recover the life, and the far better and deeper magic, that is waiting out there, for our children and for us.
Significantly, though, the early “natural philosophers" spent at least as much of their time on what we would call alchemy as what we would now call chemistry. Indeed, many celebrated figures now remembered for their scientific contributions—like the physician Paracelsus and the mathematician Isaac Newton—spent far more of their time on alchemy (and in Newton’s case, astrology) than on anything resembling modern science, and made no clear distinctions between them. You might almost say that we now use alchemy for the approaches to the natural world that didn’t work out—while science is the name we give, in retrospect, to the approaches that did work out.
The idea of technology as the triumph of the “device paradigm” was the theme of the life work of the philosopher Albert Borgmann. I have written more about the transition from tools to devices, and the ways that technological “instruments” extend the story of tools, in my book The Life We’re Looking For, as well as this essay that explores, from a Christian perspective, the “innovation bargain” required by every step in the story of technology.
I feel compelled to add that our two children loved and excelled at math and computer science in their teens, and now in their twenties, they are both thriving in jobs that reward their proficiency with technology. They had no trouble “catching up” with the tech stack of the modern workplace. For that matter, every glowing rectangle you’ve ever used was designed by engineers who grew up without iPhones or iPads—lack of access to our magical devices in their childhood was no impediment to their STEM success.